On-Demand Deep Learning Infrastructure
Use cloud GPUs without instance management, reservations, or time restrictions
GPUs, Hassle-Free
Currently, machine learning developers are expected to not only be experts in data science and model architecture, but also experts in Linux system adminstration, library dependency management, cloud storage technology, networking, and many others. We are helping machine learning developers get back to doing machine learning by taking care of these ancillary activities for them.
The trainML platform lets you start training models on GPUs without the fuss of server management, SSH tunnelling, or data and library management gymnastics. Whether you want to run a GPU-enabled Jupyter Notebook or run dozens of parallel model training experiments, you can be up and running with just a few clicks. Not only that, our GPUs are 90% cheaper than other providers.
Launch a notebook with a model from your local computer with one line.
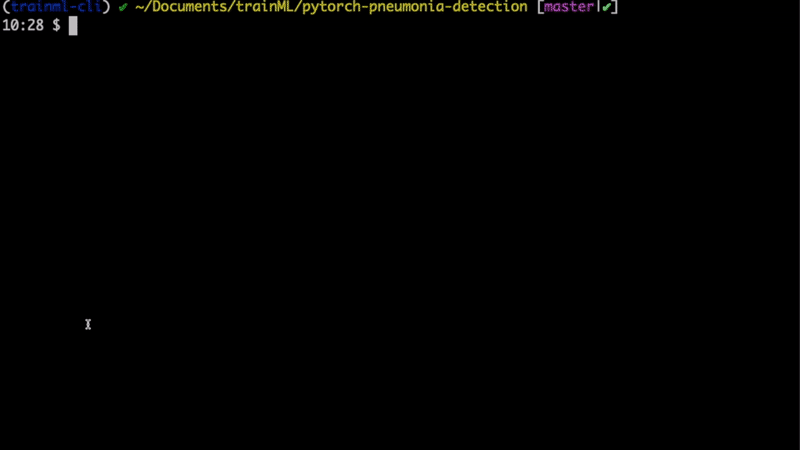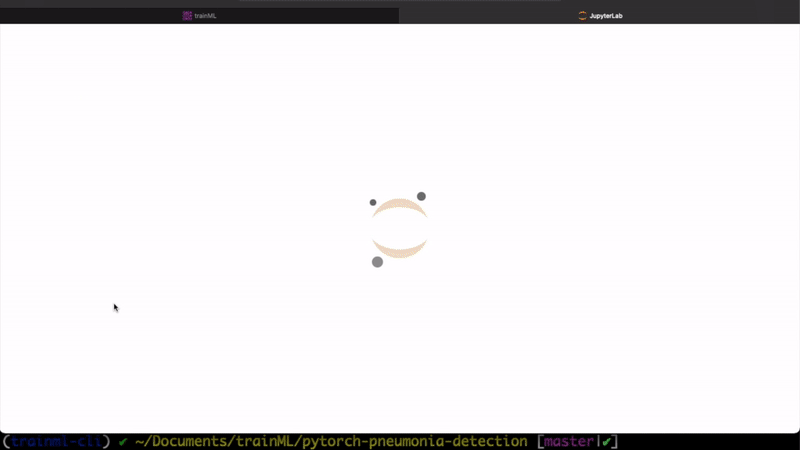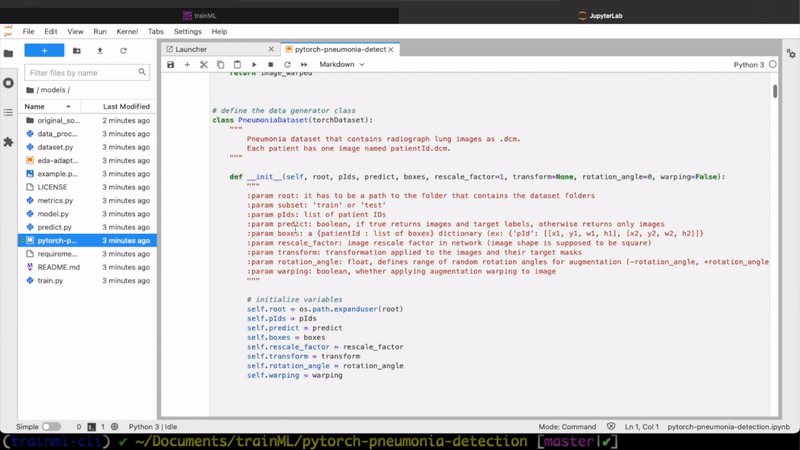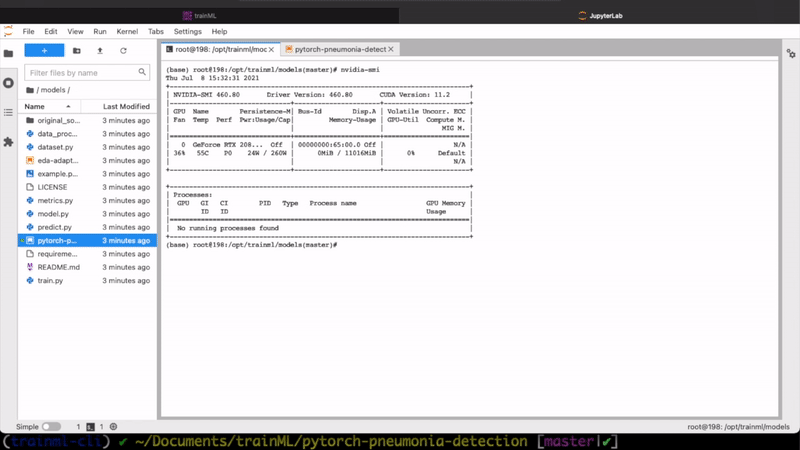
Infrastructure for your entire training and inference pipeline
Notebooks
Notebooks are full instances of JupyterLab running on up to 4 dedicated GPUs. Our pre-built conda environments are designed specifically for machine learning model training on GPUs, with the latest Tensorflow, PyTorch, MXNet, and others are pre-installed.
Learn More
Training Jobs
Training Jobs allow you to effortlessly run parallel model training experiments across dozens of GPUs. Just provide the model's git repository and the location of the data, we handle the rest. No instance provisioning, environment setup, or worrying about turning it off when you're done.
Learn MoreInference Jobs
Inference Jobs allow you to run new data through trained models and deliver the results back without any concern for managing, scaling, or descaling server clusters.
Learn MoreEndpoints
Endpoints deploy your models as a REST API. They are fully managed, giving you the real-time predictions you need for production applications without having to worry about servers, certificates, networking, or web development.
Learn MoreDatasets
Persistent Datasets allow you to reuse training data across multiple notebooks or training jobs. You can populate them directly from your local computer or another cloud provider.
Learn MoreModels
Models enable you to store an immutable version of model code and its artifacts for reuse in other jobs. Models can be populated by saving notebooks, running training jobs, or even downloaded from external sources.
Learn MoreSee how it works
Customer Stories
Save Time AND Money
trainML's mission is to help customers derive maximum value from their machine learning efforts at the lowest possible cost. While the platform itself saves you effort, our unique payment model ensures you never pay more than your budget. Our job system prevents unnecessary usage fees by automatically stopping jobs when training is complete. Best of all, the GPUs themselves have the best speed to cost ratio in the market. You can choose from the following GPU types:
GTX 1060 | $0.10/hr
4.5 TFLOPS (fp32)
6 GB GPU RAM
RTX 2060 Super | $0.25/hr
7.1 TFLOPS (fp32)
8 GB GPU RAM
RTX 2070 Super | $0.28/hr
9 TFLOPS (fp32)
8 GB GPU RAM
RTX 2080 Ti | $0.35/hr
13.5 TFLOPS (fp32)
11 GB GPU RAM
RTX 3090 | $0.98/hr
35.5 TFLOPS (fp32)
24 GB GPU RAM
Cost Comparison
Using the official tensorflow models, we trained a resnet model on the cifar10 dataset with a batch size of 1024 on our instance types as well as AWS SageMaker. The result show over 90% cost savings using trainML instances.
| Instance Type | Training Duration (hrs) | $/hr | Total Training Cost | Savings % |
| aws ml.p3.2xlarge | 0.64 | $3.83 | $2.45 | n/a |
| trainML RTX 3090 | 0.35 | $0.98 | $0.34 | 87% |
| trainML RTX 2080 Ti | 0.68 | $0.35 | $0.24 | 90% |
| trainML RTX 2070 Super | 0.89 | $0.28 | $0.25 | 90% |
| trainML RTX 2060 Super | 1.01 | $0.25 | $0.25 | 90% |
| trainML GTX 1060 | 1.66 | $0.10 | $0.17 | 93% |